Почему количество ядер в процессорах не растет больше нескольких штук
В одной из предыдущих статей я рассказал, почему рост частоты процессоров застопорился на нескольких гигагерцах. Теперь же поговорим о том, почему развитие числа ядер в пользовательских процессорах также идет крайне медленно: так, первый честный двухядерный процессор (где оба ядра были в одном кристалле), построенный на архитектуре x86, появился аж в 2006 году, 12 лет назад — это была линейка Intel Core Duo. И с тех пор 2-ядерные процессоры с арены не уходят, более того — активно развиваются: так, буквально на днях вышел ноутбук Lenovo с процессором, построенном на новейшем (для архитектуры x86) 10 нм техпроцессе. И да, как вы уже догадались, этот процессор имеет ровно 2 ядра.
Для пользовательских процессоров число ядер застопорилось на 6 еще с 2010 года, с выходом линейки AMD Phenom X6 — да, AMD FX не были честными 8-ядерными процессорами (там было 4 APU), равно как и Ryzen 7 представляет собой два блока по 4 ядра, расположенные бок о бок на кристалле. И тут, разумеется, возникает вопрос — а почему так? Ведь те же видеокарты, будучи в 1995-6 годах по сути «одноголовыми» (то есть имевшими 1 шейдер), сумели к текущему времени нарастить их число до нескольких тысяч — так, в Nvidia Titan V их аж 5120! При этом за гораздо больший срок развития архитектуры x86 пользовательские процессоры остановились на честных 6 ядрах на кристалле, а CPU для высокопроизводительных ПК — на 18, то есть на пару порядков меньше, чем у видеокарт. Почему? Об этом и поговорим ниже.
Архитектура CPU
Изначально все процессоры Intel x86 строились на архитектуре CISC (Complex Instruction Set Computing, процессоры с полным набором инструкций) — то есть в них реализовано максимальное число инструкций «на все случаи жизни». С одной стороны, это здорово: так, в 90-ые годы CPU отвечал и за рендеринг картинки, и даже за звук (был такой лайфхак — если игра тормозит, то может помочь отключение в ней звука). И даже сейчас процессор является эдаким комбайном, который может все — и это же является и проблемой: распараллелить случайную задачу на несколько ядер — задача не тривиальная. Допустим, с двумя ядрами можно сделать просто: на одно ядро «вешаем» систему и все фоновые задачи, на другое — только приложение. Это сработает всегда, но вот прирост производительности будет далеко не двукратным, так как обычно фоновые процессы требуют существенно меньше ресурсов, чем текущая тяжелая задача.
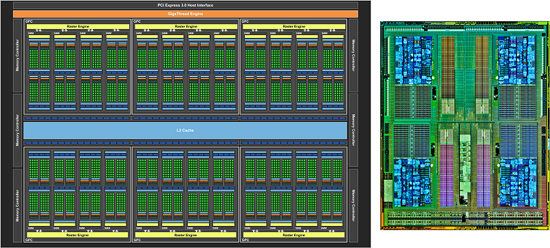
Слева — схема GPU Nvidia GTX 980 Ti, где видно 2816 CUDA-ядер, объединенных в кластеры. Справа — фотография кристалла процессора AMD Ryzen, где видно 4 больших ядра.
А теперь представим, что у нас не два, а 4 или вообще 8 ядер. Да, в задачах по архивации и другим расчетам распараллеливание работает хорошо (и именно поэтому те же серверные процессоры могут иметь и несколько десятков ядер). Но что если у нас задача со случайным исходом (которых, увы, большинство) — допустим, игра? Ведь тут каждое новое действие зависит всецело от игрока, поэтому «раскидывание» такой нагрузки на несколько ядер — задача не из простых, из-за чего разработчики зачастую «руками» прописывают, чем занимаются ядра: так, к примеру, одно может быть занято только обработкой действий искусственного интеллекта, другое отвечать только за объемный звук, и так далее. Нагрузить таким способом даже 8-ядерный процессор — практически невозможно, что мы и видим на практике.
С видеокартами же все проще: GPU, по сути, занимается расчетами и только ими, причем число разновидностей расчетов ограничено и невелико. Поэтому, во-первых, можно оптимизировать сами вычислительные ядра (у Nvidia они называются CUDA) именно под нужные задачи, а, во-вторых — раз все возможные задачи известны, то процесс их распараллеливания трудностей не вызывает. И в-третьих, управление идет не отдельными шейдерами, а вычислительными модулями, которые включают в себя 64-192 шейдера, поэтому большое число шейдеров проблемой не является.
Энергопотребление
Одной из причин отказа от дальнейшей гонки частот — резкое увеличение энергопотребления. Как я уже объяснял в статье с замедлением роста частоты CPU, тепловыделение процессора пропорционально кубу частоты. Иными словами, если на частоте в 2 ГГц процессор выделяет 100 Вт тепла, что в принципе можно без проблем отвести воздушным кулером, то на 4 ГГц получится уже 800 Вт, что возможно отвести в лучшем случае испарительной камерой с жидким азотом (хотя тут следует учитывать, что формула все же приблизительная, да и в процессоре есть не только вычислительные ядра, но получить порядок цифр с ее помощью вполне можно).
Поэтому рост вширь был отличным выходом: так, грубо говоря, двухядерный 2 ГГц процессор будет потреблять 200 Вт, а вот одноядерный 3 ГГц — почти 340, то есть выигрыш по тепловыделению больше чем на 50%, при этом в задачах с хорошей оптимизацией под многопоточность низкочастотный двухядерный CPU будет все же быстрее высокочастотного одноядерного.

Пример испарительной камеры с жидким азотом для охлаждения экстремально разогнанных CPU.
Казалось бы — это золотое дно, быстро делаем 10-ядерный процессор с частотой в 1 ГГц, который будет выделять лишь на 25% больше тепла, чем одноядерный CPU с 2 ГГц (если 2 ГГц процессор выделяет 100 Вт тепла, то 1 ГГц — всего 12.5 Вт, 10 ядер — около 125 Вт). Но тут мы быстро упираемся в то, что далеко не все задачи хорошо распараллеливаются, поэтому на практике зачастую будет получаться так, что гораздо более дешевый в производстве одноядерный CPU с 2 ГГц будет существенно быстрее гораздо более дорогого 10-ядерного, но с 1 ГГц. Но все же такие процессоры есть — в серверном сегменте, где проблем с распараллеливанием задач нет, и 40-60 ядерный CPU с частотами в 1.5 ГГц зачастую оказывается в разы быстрее 8-10 ядерных процессоров с частотами под 4 ГГц, выделяя при этом сравнимое количество тепла.
Поэтому производителям CPU приходится следить за тем, чтобы при росте ядер не страдала однопоточная производительность, а с учетом того, что предел отвода тепла в обычном домашнем ПК был «нащупан» уже достаточно давно (это около 60-100 Вт) — способов увеличения числа ядер при такой же одноядерной производительности и таком же тепловыделении всего два: это или оптимизировать саму архитектуру процессора, увеличивая его производительность за такт, или же уменьшать техпроцесс. Но, увы, и то и другое идет все медленнее: за более чем 30 лет существования x86 процессоров «отполировано» уже почти все, что можно, поэтому прирост идет в лучшем случае 5% за поколение, а уменьшение техпроцесса дается все труднее из-за фундаментальных проблем создания корректно функционирующих транзисторов (при размерах в десяток нанометров уже начинают сказываться квантовые эффекты, трудно изготовить подходящий лазер, и т.д.) — поэтому, увы, увеличивать число ядер все сложнее.
Размер кристалла
Если мы посмотрим на площадь кристаллов процессоров лет 15 назад, то увидим, что она составляет всего около 100-150 квадратных миллиметров. Около 5-7 лет назад чипы «доросли» до 300-400 кв мм и… процесс практически остановился. Почему? Все просто — во-первых, производить гигантские кристаллы очень сложно, из-за чего резко возрастает количество брака, а, значит, и конечная стоимость CPU.
Во-вторых, возрастает хрупкость: большой кристалл может очень легко расколоть, к тому же разные его края могут греться по-разному, из-за чего опять же может произойти его физическое повреждение.

Сравнение кристаллов Intel Pentium 3 и Core i9.
Ну и в-третьих — скорость света также вносит свое ограничение: да, она хоть и велика, но не бесконечна, и с большими кристаллами это может вносить задержку, а то и вовсе сделать работу процессора невозможной.
В итоге максимальный размер кристалла остановился где-то на 500 кв мм, и вряд ли уже будет расти — поэтому чтобы увеличивать число ядер, нужно уменьшать их размеры. Казалось бы — та же Nvidia или AMD смогли это сделать, и их GPU имеют тысячи шейдеров. Но тут следует понимать, что шейдеры полноценными ядрами не являются — к примеру, они не имеют собственного кэша, а только общий, плюс «заточка» под определенные задачи позволила «выкинуть» из них все лишнее, что опять же сказалось на их размере. А CPU же не только имеет полноценные ядра с собственным кэшем, но зачастую на этом же кристалле расположена и графика, и различные контроллеры — так что в итоге опять же чуть ли не единственные способы увеличения числа ядер при том же размере кристалла — это все та же оптимизация и все то же уменьшение техпроцесса, а они, как я уже писал, идут медленно.
Оптимизация работы
Представим, что у нас есть коллектив людей, выполняющих различные задачи, некоторые из которых требуют работы нескольких человек одновременно. Если людей в нем двое — они смогут договориться и эффективно работать. Четверо — уже сложнее, но тоже работа будет достаточно эффективной. А если людей 10, а то и 20? Тут уже нужно какое-то средство связи между ними, в противном случае в работе будут встречаться «перекосы», когда кто-то будет ничем не занят. В процессорах от Intel таким средством связи является кольцевая шина, которая связывает все ядра и позволяет им обмениваться информацией между собой.
Но даже и это не помогает: так, при одинаковых частотах 10-ядерный и 18-ядерный процессоры от Intel поколения Skylake-X различаются по производительности всего на 25-30%, хотя должны в теории аж на 80%. Причина как раз в шине — какой бы хорошей она не была, все равно будут возникать задержки и простои, и чем больше ядер — тем хуже будет ситуация. Но почему тогда таких проблем нет в видеокартах? Все просто — если ядра процессора можно представить людьми, которые могут выполнять различные задачи, то вычислительные блоки видеокарт — это скорее роботы на конвейере, которые могут выполнять только определенные инструкции. Им по сути «договариваться» не нужно — поэтому при росте их количества эффективность падает медленнее: так, разница в CUDA между 1080 (2560 штук) и 1080 Ti (3584 штуки) — 40%, на практике же около 25-35%, то есть потери существенно меньше.
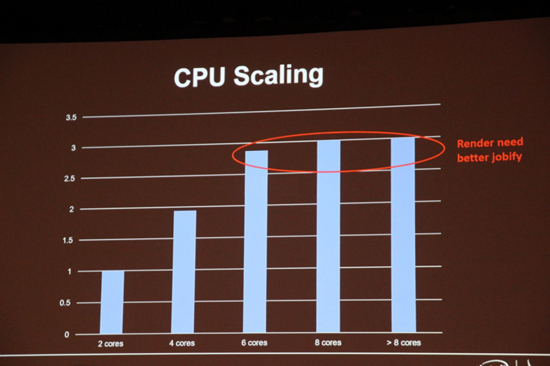
Чем больше ядер, тем хуже они работают вместе, вплоть до нулевого прироста производительности при увеличении числа ядер.
Поэтому число ядер особого смысла наращивать нет — прирост от каждого нового ядра будет все ниже. Причем решить эту проблему достаточно трудно — нужно разработать такую шину, которая позволяла бы передавать данные между любыми двумя ядрами с одинаковой задержкой. Лучше всего в таком случае подходит топология звезда — когда все ядра должны быть соединены с концентратором, но на деле такой реализации еще никто не сделал.
Так что в итоге, как видим, что наращивание частоты, что наращивание числа ядер — задача достаточно сложная, а игра при этом зачастую не стоит свеч. И в ближайшем будущем вряд ли что-то серьезно изменится, так как ничего лучше кремниевых кристаллов пока еще не придумали.
Источник: iguides.ru
{kind=link}
Еще никто не комментировал данный материал.
Написать комментарий